Context Engineering: cuándo usar CLAUDE.md, Skills, Prompts y Subagentes
Guía práctica para entender los cuatro pilares del context engineering y dejar de lidiar con agentes que inventan convenciones, ignoran reglas o se desvían a mitad de la tarea.

Este es el resumen práctico de la clase “Context Engineering con Claude Code”. Si te perdiste la sesión, en esta guía te dejamos las reglas, los antipatrones y los criterios para decidir qué pieza usar en cada momento.
Puedes ver la grabación de la clase aquí. Recomendamos verla para tener el contexto completo de cada decisión.
Por qué un agente “olvida”
Cuando abres un chat nuevo en Claude Code, Cursor u OpenCode, el chat arranca en cero. No conoce tus convenciones, tu stack, ni cómo se comporta tu equipo. Por eso el prompt solo no alcanza: necesitas contexto persistente.
El context engineering es exactamente eso: diseñar qué información vive dónde, por cuánto tiempo, y con qué costo en tokens, para que el agente se comporte consistente entre sesiones.
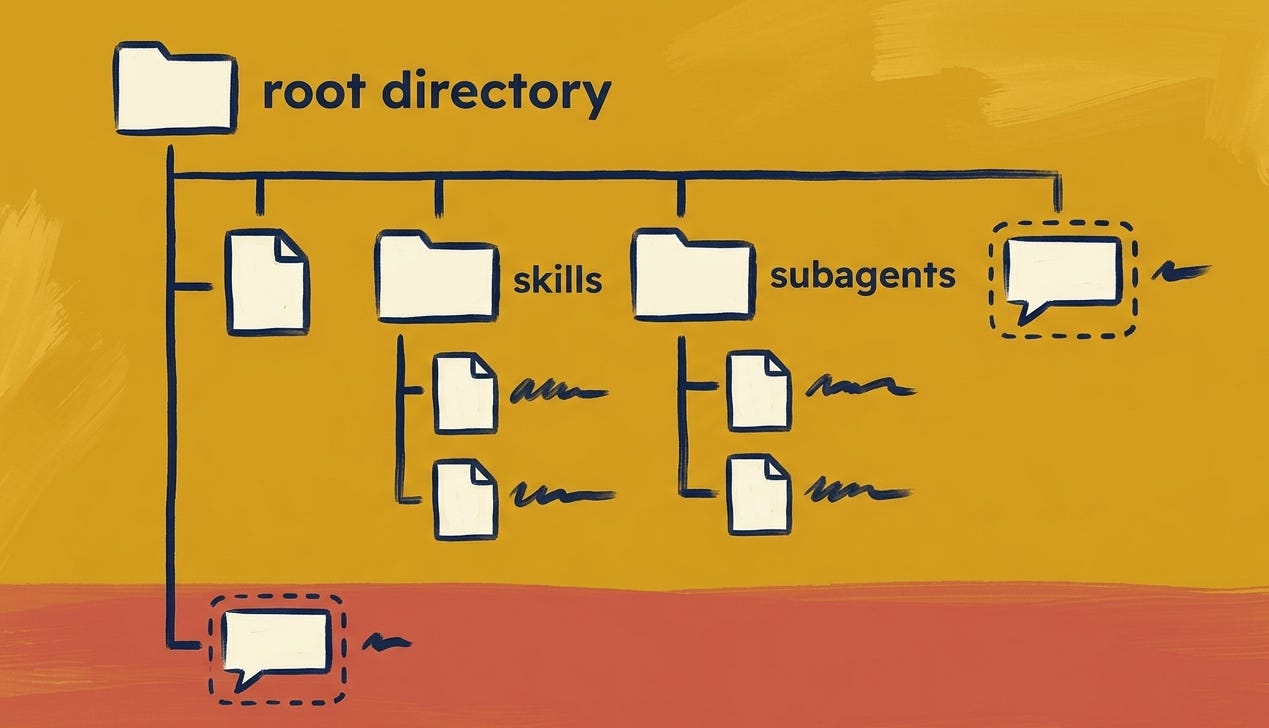
Hay cuatro herramientas para hacerlo, y cada una resuelve un problema distinto:
Prompts: instrucciones de un solo turno.
CLAUDE.md: el contrato persistente del proyecto, se llama CLAUDE.md en el caso de Claude, esto cambia dependiendo de la plataforma que uses.
Skills: capacidades invocadas bajo demanda.
Subagentes: sesiones hijas con contexto aislado.
El error más común es usar la herramienta equivocada para el problema. Veamos cada una para usarlas de forma correcta:
1. CLAUDE.md: el contrato persistente del proyecto
CLAUDE.md es el archivo que Claude Code carga al inicio de cada sesión nueva (cada chat nuevo). No es documentación del proyecto, sino un contrato puntual de reglas de comportamiento.
La regla de oro: 200 líneas máximo
Si tu CLAUDE.md tiene 500 líneas, ya está mal. Cada línea consume tokens en cada sesión y, después de cierto volumen, el modelo empieza a ignorar reglas o a entrar en conflicto con el prompt.
Antipatrones: lo que NO debe ir en CLAUDE.md
Documentación gigantesca del proyecto.
Stack completo con versiones de cada librería.
Historial del proyecto.
Estructura del repositorio.
Comandos específicos por ambiente (mejor algo generalizado).
Esquemas de base de datos.
Control de versiones dentro del archivo (un contador de versiones sí, el changelog no).
Reglas de linter (un linter debe hacer el trabajo, no el LLM).
Copiar el README.
Las tres preguntas que validan cada línea
Antes de agregar cualquier cosa a CLAUDE.md, pregúntate:
Sin esta línea, ¿el agente se equivoca de forma reproducible?
¿Esto podría ser manejado por un linter, formatter o pre-commit hook?
¿Esta información se desactualizará en semanas?
Si la respuesta a la 1 es “no” o a la 2/3 es “sí”, la línea no va.
Jerarquía: enterprise, proyecto, usuario
CLAUDE.md trabaja en tres niveles que se concatenan:
Enterprise: se ejecuta siempre, a nivel organización.
Proyecto: aislado por repo (puedes tener uno en tu frontend, otro en tu backend, otro en mobile).
Usuario: tus preferencias globales, viven en ~/.claude/CLAUDE.md.
Importante: cada nivel suma tokens, por eso la regla de las 200 líneas aplica especialmente cuando trabajas con jerarquías completas.
Agnóstico entre LLMs
CLAUDE.md funciona con cualquier modelo dentro de Claude Code (Opus, Sonnet, Haiku). Y el patrón es trasladable: Gemini usa GEMINI.md, Codex usa codex.md, OpenCode usa AGENTS.md, es el mismo protocolo con distinto nombre.
2. Skills: capacidades invocadas bajo demanda
Mientras CLAUDE.md se carga siempre, una Skill se carga solo cuando aplica. Esa es la diferencia clave.
Anatomía de una Skill
Una Skill tiene cuatro componentes:
Nombre: el identificador.
Descripción: lo más crítico. El modelo solo lee la descripción para decidir si invoca la Skill, si la descripción es vaga, la Skill no se llama cuando debería.
Cuerpo: la lógica.
Glob (opcional): patrones de archivos que disparan la Skill automáticamente. Por ejemplo,
*/*.test.tspara que se invoque al tocar tests.
Dos formas de invocar
Explícita: escribes el nombre en el chat: /review-pr 42
Implícita: el modelo decide invocarla porque la descripción matchea con lo que estás pidiendo, o porque el glob matchea con los archivos que estás tocando.
Por qué la descripción importa tanto
El modelo escanea las descripciones de todas tus Skills y solo carga el cuerpo de la que decide usar. Si tu descripción dice “skill útil para código”, nunca se va a llamar, en cambio si dice “Úsala cuando el usuario pida revisar un PR, hacer code review, o decir ‘revisa el PR número X’”, el match es claro.
3. Subagentes: contexto aislado en una sesión hija
Un subagente abre una sesión hija con su propio contexto, le delegas una tarea específica, hace su trabajo en aislamiento, y te devuelve solo el resultado a la sesión principal.
Cuándo SÍ usar subagentes
Investigación o lectura de grandes volúmenes de contexto.
Tareas con consumo enorme de tokens que se justifica aislar.
Output bien definido y estructurado.
Cuándo NO usar subagentes
Tareas pequeñas con bajo consumo de tokens (overhead innecesario).
Output ambiguo o mal estructurado.
Cuando necesitas que todo el contexto viva en la ventana principal.
Cuándo usar cada herramienta
Regla mental rápida:
¿Aplica una sola vez? → Prompt.
¿Aplica a todo el proyecto siempre? → CLAUDE.md.
¿Aplica a un subset recurrente? → Skill.
¿Necesita aislar mucho contexto? → Subagente.
Síntomas de un agente que se desvía (y cómo arreglarlos)
Cuando tu agente empieza a comportarse “raro” casi siempre es uno de estos cinco síntomas:
1. Inventa convenciones
Causa: CLAUDE.md es vago o le faltan reglas.
Fix: agrega la regla específica que faltaba. Pero antes pasa las tres preguntas.
2. Usa la Skill equivocada
Causa: la descripción de la Skill no es clara o precisa.
Fix: reescribe la descripción con ejemplos de cuándo debe invocarse.
3. Hace lo opuesto a lo solicitado
Causa: el prompt compite contra CLAUDE.md.
Fix: revisa la consistencia entre tu prompt y tu archivo de contexto. Si CLAUDE.md dice “siempre usa Vitest” y el prompt dice “escribe tests con Jest”, el modelo no sabe a quién hacer caso.
4. Ignora reglas específicas
Causa: CLAUDE.md tiene demasiado contenido o reglas en conflicto interno.
Fix: reescribe y encapsula. Menos líneas, menos conflictos.
Cómo gestionar CLAUDE.md a nivel de equipo
Tres recomendaciones de equipos que ya están trabajando así:
Versionar el archivo en el repo, igual que cualquier código.
Establecer un convenio general en sesiones de revisión, cuando alguien propone una nueva regla, se discute antes de hacer merge.
El Tech Lead suele tener el control de las modificaciones a CLAUDE.md. No es una responsabilidad para dejar a perfiles junior, porque un cambio mal hecho afecta a todo el equipo.
Qué seguir explorando
Hooks: scripts que corren automáticamente antes/después de ediciones (Prettier, type-check, etc.).
MCPs: conecta Claude Code a GitHub, Linear, Figma, Postgres, lo que tengas en tu stack.
Flujos SDD con subagentes + skills: una skill que invoca implícitamente un subagente especializado en análisis de specs, para generar tickets bien estructurados.
Lleva esto al siguiente nivel con Hardcore AI
Si construir agentes con context engineering te parece útil, Hardcore AI es el programa donde aprendes a hacer esto sistemáticamente: Discovery, arquitectura, implementación y despliegue de agentes de código, en cuatro semanas.
12 sesiones en vivo, mentores que están construyendo con AI todos los días , Demo Day frente a Founders de la red 30X (+3,000 ejecutivos), y acceso permanente a la comunidad de alumnis.
Aplica al programa Hardcore AI.
Continúa la conversación con developers que están construyendo con AI. Entra a la comunidad.